PDFlib TET:从文本提取到图像处理,全方位解析 PDF 文档的得力工具
原创|行业资讯|编辑:张蓉|2025-05-16 11:22:32.030|阅读
68 次
概述:在数字文档处理领域,PDF 文档因其广泛的使用和丰富的信息承载能力而占据重要地位。然而,从 PDF 中提取高质量的文本和图像信息并非易事。PDFlib TET(Text and Image Extraction Toolkit)正是为解决这一难题而生,它是一款功能强大、可靠的 PDF 文本和图像提取工具,适用于多种应用场景,帮助用户高效地挖掘 PDF 文档中的价值。
# 界面/图表报表/文档/IDE等千款热门软控件火热销售中 >>
在数字文档处理领域,PDF 文档因其广泛的使用和丰富的信息承载能力而占据重要地位。然而,从 PDF 中提取高质量的文本和图像信息并非易事。PDFlib TET(Text and Image Extraction Toolkit)正是为解决这一难题而生,它是一款功能强大、可靠的 PDF 文本和图像提取工具,适用于多种应用场景,帮助用户高效地挖掘 PDF 文档中的价值。
PDFlib TET正版试用下载
一、产品概述
PDFlib TET 可以从 PDF 文档中可靠地提取文本、图像、注释和元数据。它能够将 PDF 中的文本内容以 Unicode 字符串的形式提供,并附带详细的颜色、字形和字体信息以及在页面上的位置。对于图像,TET 能够以常见的图像格式进行提取。此外,TET 还可以选择性地将 PDF 文档转换为基于 XML 的 TETML 格式,该格式不仅包含文本和元数据,还包括资源信息。TET 内置了先进的内容分析算法,能够确定单词边界、将文本分组到列、识别表格结构以及去除冗余项(如阴影文本)。
二、丰富的功能特性
(一)文本提取功能强大
-
连字符词处理 :TET 能够检测跨越多行的连字词,删除连字符,并将各部分组合成完整单词,确保搜索完整性。这对于处理德语等使用连字符较多的语言尤其重要。
-
重音字符和连字处理 :TET 可以识别并处理重音字符和连字,将它们重新组合或分离为正确的字符形式。例如,将分别放置的 “a” 和 “¨” 组合成 “ä”,或将连字 “fi” 分离为 “f” 和 “i”。
-
首字下沉处理 :首字下沉是段落开头的较大初始字符,TET 能够正确提取完整单词,而不是将其拆分为单个初始字符和单词其余部分。
-
Unicode 映射算法 :TET 获得专利的 Unicode 映射算法实现了一种级联算法,该算法采用所有可用信息来确定 Unicode 值。对于许多有问题的文档,TET 能够提取出正确的文本,而其他产品可能只能提取到不可用的垃圾信息。
-
双向文本支持 :PDF 本身并不对逻辑文本进行编码,而只是页面上字形的容器。TET 能够对阿拉伯语和希伯来语等从右到左排列的文本进行重新排序,以创建适当的逻辑文本输出,即使文本中包含从左到右的插入物(例如西方语言中的数字或名称)。
-
修复损坏的 PDF 文档 :TET 的修复模式可以恢复多种损坏的 PDF 文档,有时即使页面无法在 Acrobat 中显示,TET 也能交付文档的页面内容。
(二)图像提取能力出色
-
图像格式转换 :TET 的图像引擎能够在 PDF 图像的特性与图像输出格式的功能之间取得平衡,无论 PDF 图像的内部结构如何,都能以常见的图像文件格式(如 JPEG、TIFF 等)提取像素图像。
-
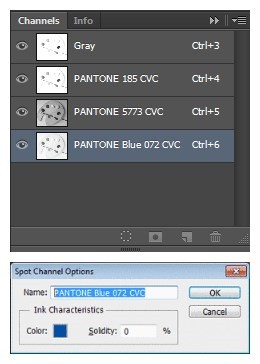
专色通道处理 :TET 支持多种颜色空间和压缩滤镜的组合。对于带有专色通道的图像,TET 创建带有专色通道的 TIFF 输出。如果需要出色的色彩保真度且不能接受任何颜色转换,这非常有用。同时,TET 还可以根据需求将专色通道转换为纯 CMYK 输出。
-
碎片图像合并 :许多 PDF 文档中的图像被生成 PDF 的软件分解为小片段。TET 能够检测碎片图像并将其合并以形成可用的较大图像。例如,Microsoft Office 应用程序和 TeX 通常会产生大量碎片图像,而 Adobe InDesign 通常将图像分成大小不一的片段。TET 的这种碎片图像合并功能使得这些图像可以被合理地重新使用。
(三)元数据与详细信息获取
TET 能够提取 PDF 文档中的元数据,如文档信息字段和 XMP 元数据。通过 pCOS 接口,用户还可以查询有关 PDF 文档的详细信息,包括字体列表、页面大小等。pCOS 接口提供了一种简单而强大的方式来访问 PDF 文档的内部结构和内容,使得用户能够深入了解文档的各个方面。
(四)文档修复能力
TET 的修复模式可以恢复多种损坏的 PDF 文档,例如由于传输错误或其他问题导致的损坏。有时,PDF 文档损坏严重,以致页面甚至无法在 Acrobat 中显示。即使在这种极端情况下,TET 仍然能够交付文档的页面内容,这使得 TET 在处理损坏的 PDF 文档时具有很高的实用价值。
三、应用场景广泛
(一)搜索引擎 PDF 索引器
TET 可用于实现搜索引擎的 PDF 索引器,帮助搜索引擎更好地索引和检索 PDF 文档中的内容。通过将 PDF 文档中的文本内容提取出来并转换为 Unicode 字符串,搜索引擎可以更准确地识别和索引文档中的关键词和短语,从而提高搜索结果的相关性和准确性。
(二)文本和图像再利用
用户可以重新利用 PDF 中的文本和图像,将其用于其他文档、报告或创意项目中。例如,将 PDF 文档中的图表、图片和文本提取出来,用于创建新的演示文稿、报告或宣传材料。TET 提取的高质量文本和图像使得这些内容可以轻松地被重新利用和整合到新的项目中。
(三)PDF 内容转换
TET 能够将 PDF 的内容转换为其他格式,如 XML、HTML 或文本文件,方便用户在不同系统和应用程序之间共享和使用信息。这种转换功能使得用户可以将 PDF 文档中的内容导入到其他软件中进行进一步的处理和分析,打破了 PDF 文档格式的限制,提高了信息的流动性和可用性。
(四)基于内容的 PDF 处理
结合 PDFlib + PDI,TET 可以根据 PDF 的内容进行处理,例如根据标题进行拆分,以实现更灵活的文档管理。这种基于内容的处理方式使得用户能够根据文档的实际内容进行个性化的处理和操作,提高了文档处理的自动化程度和效率。
(五)页面内容检查
TET 可以检查页面上的特定位置是否为空,这对于在 PDF 文档中放置条形码、图章或其他标记非常有用。例如,在生成 PDF 文档时,需要确保某些特定位置没有内容,以便放置新的标记或信息。TET 的这种检查功能可以帮助用户避免内容重叠和格式混乱的问题,保证文档的质量和专业性。
总结
PDFlib TET 凭借其强大的功能和广泛的应用场景,成为处理 PDF 文档的得力助手。从文本和图像的提取,到元数据的获取和文档的修复,TET 都提供了高效、可靠的解决方案。无论是企业级的文档管理、搜索引擎优化,还是创意设计和内容再利用,TET 都能够充分发挥 PDF 文档的价值,帮助用户实现更高效的工作流程和更出色的结果。
慧都是⼀家⾏业数字化解决⽅案公司,专注于软件、⽯油与⼯业领域,以深⼊的业务理解和⾏业经验,帮助企业实现智能化转型与持续竞争优势。
慧都科技作为 PDFlib 的中国区合作伙伴,致力于为企业提供先进的技术解决方案。PDFlib 专注于 PDF 技术领域,自成立以来,始终关注行业发展趋势并积极创新。PDFlib 的产品凭借强大的功能和广泛的市场覆盖,被全球众多企业所信赖,广泛应用于科研、工程、金融等多个关键领域。其文本和图像提取工具包(TET)等产品,通过高效提取 PDF 文档中的文本、图像和元数据,帮助企业实现复杂文档内容的快速处理与深度分析。
标签:
本站文章除注明转载外,均为本站原创或翻译。欢迎任何形式的转载,但请务必注明出处、不得修改原文相关链接,如果存在内容上的异议请邮件反馈至chenjj@evget.com


 首页
首页 
















 2次
2次


 相关文章
相关文章 

 微信
微信 在线咨询
在线咨询




 渝公网安备
50010702500608号
渝公网安备
50010702500608号

 客服热线
客服热线